

I have struggled with one client on queries that were dealing with date ranges or type ranges or many filters, on very large tables with low density in many cases, and you knew one index would really improves it but it was based on some filter that was undeterministic.
Let's take a classic example, you have a website / an api that queries the orders that are not yet completed per accounts and for the last day.
On sql server, you have many indexes that can help and data partitioning can as well but in some case, you have a query that has so many filters and it does only care about the last day or even more precised... the last hour.
You know this index would be huge if you do not use a filter and your DML operation would suffer greatly!
Additionally your table is not very dense with tons of columns (well you did not design the table and you are , sure frustrated, but you got to deal with the current design).
Finally the query is like one of the most frequently executed on your platform.
It there a solution?
YES!
The solution is with filtered indexes! It is nice because it is a standard or wed edition features and therefore you can use it at ease.
As the index stays very small, due to the fact that it only cares about the last rows (for example 100K rows intead of the 40 million rows) and the reindex takes about 2-3 seconds online (entreprise edition) and 1 second offline.
So even on standard edition the blockage would not be dramatic.
So let's do an example.
Let's asume I have an order table.
First let's prepare the table:
CREATE DATABASE DynFilteredIndexes
GO
USE DynFilteredIndexes
GO
CREATE Schema Orders authorization dbo
GO
CREATE TABLE Orders.Header
(OrderId int identity(1,1) not null,
DateOrdered datetime not null,
AccountId smallint not null,
OrderTotal decimal(18,2) not null,
OrderStatusId tinyint not null,
)
GO
ALTER TABLE Orders.Header ADD CONSTRAINT PK_OrdersHeader PRIMARY KEY CLUSTERED (OrderId)
GO
SELECT top 20000
CONVERT(SMALLINT,ROW_NUMBER() OVER (Order by A.Object_Id)) AccountId
INTO #AccountId
FROM Sys.Objects A CROSS JOIN Sys.Objects B CROSS JOIN Sys.Objects C
GO
SELECT top 30000
CONVERT(SMALLINT,ROW_NUMBER() OVER (Order by A.Object_Id)) Day
INTO #DayId
FROM Sys.Objects A CROSS JOIN Sys.Objects B CROSS JOIN Sys.Objects C
GO
SELECT top 1000
CONVERT(DECIMAL(18,2),ROW_NUMBER() OVER (Order by A.Object_Id))*100.0 OrderTotal
INTO #OrderTotal
FROM Sys.Objects A CROSS JOIN Sys.Objects B CROSS JOIN Sys.Objects C
GO
DECLARE @Rand int , @row int, @AccountIdFrom int, @AccountIdto int, @OTFrom int, @OTTo int
DECLARE @Cnt int = 1
WHILE @Cnt < 5000
BEGIN
SET @Rand = RAND()*1000
SET @Row = RAND() * 20000
SET @AccountIdFrom = RAND() * @Rand
SET @AccountIdTo = RAND() * @Row
SET @OTFrom = RAND() * @AccountIdTo
SET @OTTo = RAND() * @AccountIdTo
SELECT @Rand, @Row, @AccountIdFrom, @AccountIdTo,@OTFrom, @OTTo, @Rand % 2 + @Row % 2 + @AccountIdFrom % 2
INSERT INTO Orders.Header
(AccountId, DateOrdered, OrderTotal, OrderStatusId)
SELECT TOP (@Row) Accountid, DATEADD(DAY, -Day, GETDATE()) DateOrdered, OrderTotal, @Rand % 2 + @Row % 2 + @AccountIdFrom % 2 OrderStatusId FROM #AccountId A CROSS JOIN #DayId B CROSS JOIN #OrderTotal C
WHERE AccountId BETWEEN @AccountIdFrom AND @AccountIdTo
AND OrderTotal BETWEEN @OTFrom AND @OTTo
SET @Cnt = @cnt + 1
END
GO
Let's see how many rows we have then per date, account id, order total , status to see how random we have inserted in the order table:

Counts : statistical distribution of the randomization
Let's now add indexes :
Classic indexes:
CREATE INDEX IX_OrdersHeaderDateOrdered ON Orders.Header (Dateordered)
CREATE INDEX IX_OrdersHeaderAccountId ON Orders.Header (AccountId)
The index filtered :
CREATE INDEX IX_FilteredLastDay ON Orders.Header(AccountId, OrderStatusId)
INCLUDE (OrderTotal)
WHERE DateOrdered > '20170219'
is instantaneously created due to the index on dateordered previously created.
Note that this index cannot be created :
CREATE INDEX IX_FilteredLastDay ON Orders.Header(AccountId, OrderStatusId)
INCLUDE (OrderTotal)
WHERE DateOrdered > DATEADD(DAY,-2,GETDATE())
Msg 10735, Level 15, State 1, Line 4
Incorrect WHERE clause for filtered index 'IX_FilteredLastDay' on table 'Orders.Header'.Error:
When I calculate the size of the indexes:
SELECT
@@SERVERNAME AS ServerName,
DIPS.database_id AS DatabaseId,
'DynFilteredIndexes' AS DatabaseName,
DIPS.OBJECT_ID AS TableId,
O.name AS TableName,
DIPS.index_id AS IndexId,
I.name AS IndexName,
s.name AS SchemaName,
DIPS.partition_number AS PartitionNo,
DIPS.alloc_unit_type_desc AS AllocUnitTypeDesc,
DIPS.page_count AS PageCount,
p.rows AS RowsCount,
DIPS.avg_fragmentation_in_percent AS Frag,
GETDATE() AS DateChecked,
DIPS.index_type_desc AS IndexType
FROM sys.dm_db_index_physical_stats (23, NULL, NULL , NULL, 'DETAILED') AS DIPS
INNER JOIN [DynFilteredIndexes].sys.partitions AS P ON DIPS.object_id = P.object_id
AND DIPS.index_id = P.index_id
AND DIPS.partition_number = P.partition_number
INNER JOIN [DynFilteredIndexes].sys.indexes AS I ON P.object_id = I.object_id
AND P.index_id = I.index_id
INNER JOIN [DynFilteredIndexes].sys.objects AS O ON I.object_id = O.object_id AND O.type = 'U'
INNER JOIN [DynFilteredIndexes].sys.schemas AS S ON O.schema_id = S.schema_id
WHERE DIPS.page_count < 10000
The result is clear:
The filtered index has only 2161 rows for 8 data pages, no wonder it was created super fast!

index size (rows and pages)
Then we can look at the performance:
Here are three Selects (using "*" to include all columns but we can obviously list the columns which is a better practice):
SELECT * FROM Orders.Header WITH (INDEX = IX_FilteredLastDay) WHERE DateOrdered > '20170219' AND AccountId = 18
GO
SELECT * FROM Orders.Header WITH (INDEX= IX_OrdersHeaderAccountId) WHERE DateOrdered > '20170219' AND AccountId = 18
GO
SELECT * FROM Orders.Header WITH (INDEX= IX_OrdersHeaderDateOrdered) WHERE DateOrdered > '20170219' AND AccountId = 18
GO
Here is the profiler result:

Profiler result
On the profiler result, clearly the filtered index is faster then the date then account filter, which makes sense as it is in the order of the discrimination.
Ad you can see the filtered index footprint is very very tiny: 78 io reads! and 0 ms of CPU.
It is even more clear if I add orderstatusid in the where filter with 26 io reads.

profiler result with add filter
I could even increase the performance by adding the dateordered into the list of columns as this generates a key lookup:
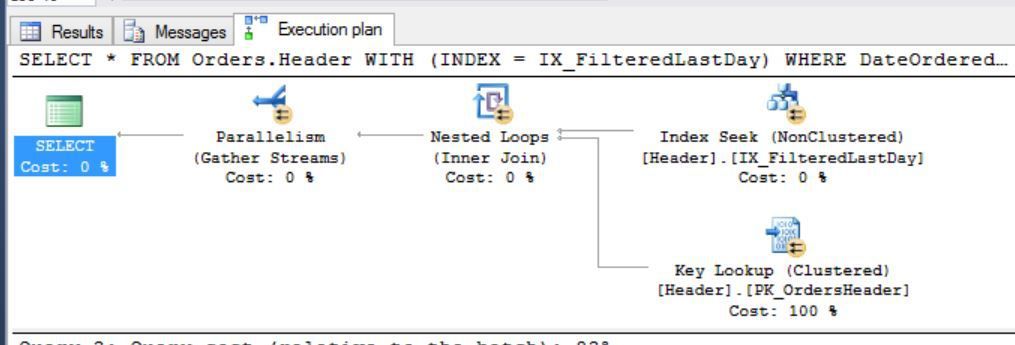
exec plan with key lookup
Well you can see that the index is really fast. The next question is how to maintain the index then???
Well you create a job that run this script once every morning:
Use DynFilteredIndexes
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
DECLARE @Date DATE = DATEADD(Day, -1, GETDATE())
DECLARE @DateStr VARCHAR(16) = REPLACE(CONVERT(VARCHAR,@Date),'-','')
DECLARE @Stmt VARCHAR(MAX) =
'
CREATE INDEX IX_FilteredLastDay ON Orders.Header(AccountId, OrderStatusId)
INCLUDE (OrderTotal)
WHERE DateOrdered > '''+@DateStr+'''
WITH (ONLINE = ON, DROP_EXISTING=ON)
'
print @stmt
EXEC (@Stmt)
It will run in 1 second and will give you a very nice index! (no real DML impact and super dast querying!)
t-sql script is included below.
I hope you had a nice reading!
Best!


